Voice verification AI services to enhance our lives
We aim to collect and label various voice data in order to provide voice verification AI services to enhance both personal and professional lives of people.
About
An A.I. speech-to-text transcription service
Datumo provides high quality data for smarter AI. As part of Datumo's Data Sponsorship Program, Datumo cooperated with ActionPower in building the following dataset.
ActionPower aspires to unlock the potential of A.I.. Many have introduced A.I. and its potential, but not many have delivered an A.I. model in practical use. ActionPower aims to deliver a life-changing A.I. model with their research on technology and services.
Under the belief of “Action brings power”, ActionPower is an AI-based startup company that offers speech recognition and natural language processing technology services. Speech recognition requires a variety of high-tech subtechnology. ActionPower is the first in Korea to release an A.I. speech-to-text transcription service, Daglo. The startup has developed it’s own speech recognition technology and aims to release more services to enhance people’s lives using Daglo, the best service for Korean speech recognition in the world.
Daglo is the fist A.I. model of ActionPower. People record audio files from lectures, phone calls, meetings, and so on, but it is inconvenient to check the recordings because searching keywords in audio files is impossible and it takes as much time to listen as to record. However, upon speech-to-text transcription, most of the recording can be easily documented. Daglo is an A.I. based web service for automated speech-to-text transcription. It also offers editing features for the transcribed text and replays the audio file when the user clicks on a specific part of text. Number of users in Daglo is continuously growing and companies including Samsung C&T, TWC, and the local government are some of the users.
Testimonial
“We were able to build datasets that enhance the accuracy of speech recognition. Within a short amount time, much data were collected and pre-processed in the appropriate format for A.I. training. We will do our best to use the datasets to develop a speech recognition service that can better people’s lives.”
Dataset specification
1,196 sets of voice data (1,196 crowd-workers each submitted 1 set of voice data)
1 set of voice data consists of: 1 original text — 3 voice data(mp3) — 5tag text metadata
Total of 30 original text per original text
Process of annotation
30 short texts as inputs and 3 voice data per text as outputs / Metadata tagging on speakers and speaking environments
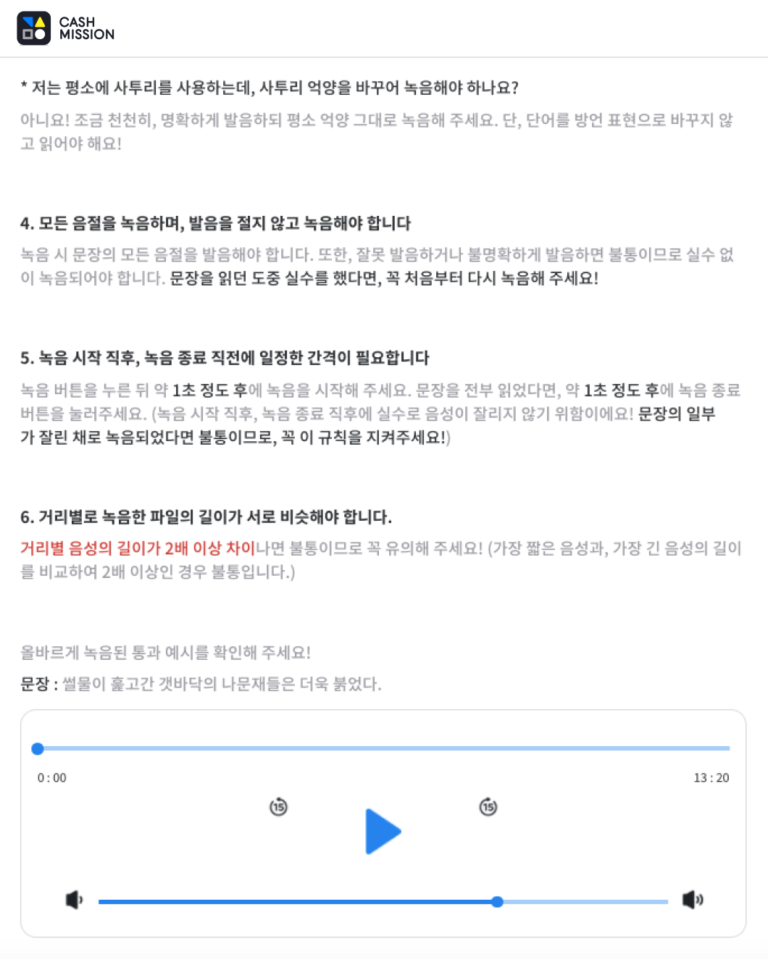
Detailed guidelines to fulfill the client's needs
Project uploaded on Cash Mission → Voice data collected
Total inspection carried out by limited number of inspectors
Data Collection
Process design optimized for cache mission launch for purposeful data collection
Full data inspection
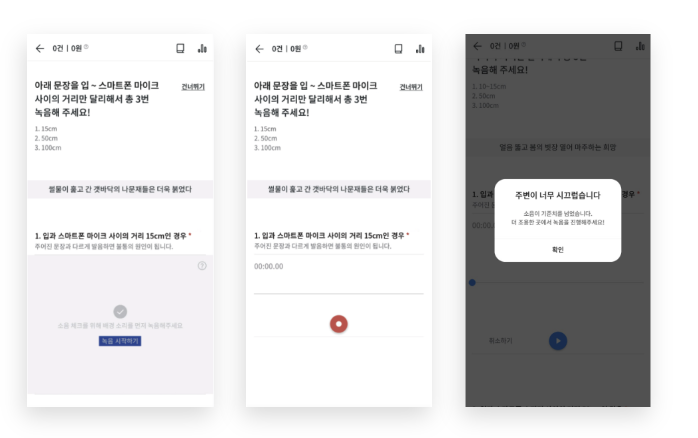
Mobile screenshot of the guideline on Cash Mission
Screenshot of the user guideline on Cash Mission(Web ver.)
Sample Data
Original text: [You should drink hot coffee and tea during the cold winter]
Data: [Recordings from various distance; 10cm, 50cm, 100cm]
Meta data: [Female, 25-years-old, Gyeonggi (province), Indoors, 25dB~50dB]
10cm
50cm
100cm
Original text: [You, the one person amongst many other]
Data: [Recordings from various distance; 10cm, 50cm, 100cm]
Meta data: [Male, 25-years-old, Gyeonggi (province), Indoors, 25dB~50dB]
10cm
50cm
100cm
Applications
Speaker recognition and separation AI
Voice recognition technology enhancement
Speech-to-Text service / application
CC BY-SA
Reusers are allowed to distribute, remix, adapt, and build upon the material in any medium or format, even commercially, so long as attribution is given to the creator. If you remix, adapt, or build upon the material, you must license the modified material under identical terms.