
InstaOrder
Approximately 1.45 million combinations of positions of two objects
TAGS
3D
Computer vision
Object detection
Occlution
Image
Accurate measurement of distance
This project aims to build datasets for the comprehension of spatial information in an image. It is part of the computer vision research of understanding the distances between objects within an image, to apply on autonomous driving, image editing, and more. Learning based approach has recently shown to be a success. However, it has its own limitations of measuring distances accurately, as it focuses only on predicting the distances between the pixels within a video data.
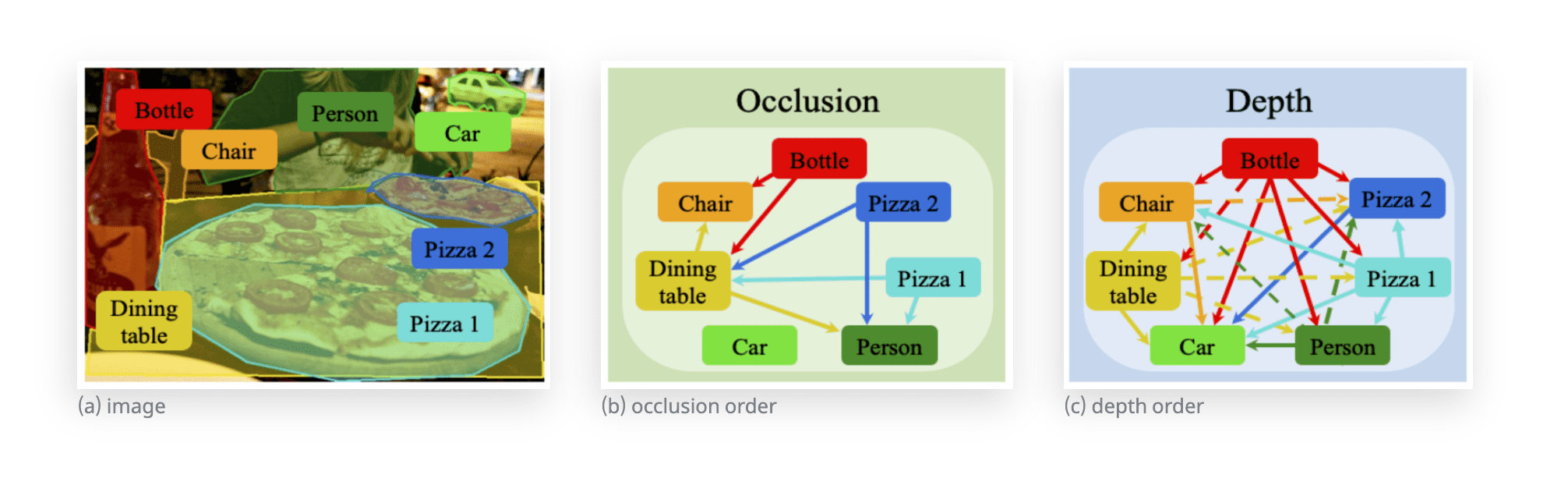
Below image(b) is the depth map result of image(a), using MiDaS v2 network, the best distance measuring method out there. There are inaccuracies in measuring the distances between the heads and the bodies, however. Computer Vision Lab set their goals to build an advanced deep learning model by defining the accuracy based on object units, rather than pixel units.
The network based on InstaOrder, the new image dataset built using 2.9million labeled images from Datumo, has proved to improve the performances of the existing pixel-based distance measurements.
Image(c) is the depth map predicted by the network trained with InstaOrder datasets. Image(b), focused on pixels, has predicted inaccurate depths of the heads. Image(c), focused on object information, has predicted accurately.

About
Most authoritative research on computer vision
Datumo provides high quality data for smarter AI. As part of Datumo's Data Sponsorship Program, Datumo cooperated with POSTECH in building the following dataset.
POSTECH is Korea’s first research university, established in a period when Korea was still chasing after advanced technologies of developed nations. It was founded on the belief that Korea needed a university that could spearhead the global science and technology community. POSTECH has been a university that constantly pioneered change and innovation in higher education.
The professors, including Minsu Cho, Suha Kwak, and Jaesik Park are continuing their research in visual correspondence, metric learning, GAN, 3D vision, and so on. Every year, they publish papers on the so called 'Top 3 most authoritative computer vision conferences', which include CVPR(Computer Vision and Pattern Recognition), ICCV(International Conference on Computer Vision), and ECCV(European Conference on Computer Vision).
Testimonial
“Using their systematic platform, Datumo quickly collected high quality data despite the large amount of data we have requested. Data quality was maintained by the user guidelines which included actual labeling examples to help the crowd-workers understand the task. The "Spy System*" also allowed us to obtain high quality data by preventing biased results, and our dedicated project manager took great care of the project. We would like to take this opportunity to thank Datumo for providing much help in our research.”
*:The "Spy System" refers to Datumo's crowd-workers monitoring system. An underperforming crowd-worker is classified as a "spy" and will be prohibited from participating in certain tasks or projects.
Dataset specification
- Number of combinations : 1,465,566 (each for Object orientation & Multirange data, and Occlusion data)
- img_file_name: COCO DATASET 2017 TRAIN & VALIDATION file: `img_id`_`object1_id`_ `object2_id`.png
- object1_id : object on left / object2_id : object on right
- Excluded from object in following cases:
- Only one object present in an image
-area <= 600
- iscrowd = 1
- Ten objects randomly selected in following case:
- More than ten objects present in an image - count
- Number of participants until final decision made
Process of annotation
The dataset consists of 2.9 million labels from 100,000 daily images, showing the geometric orders between object types. As shown in the images below, Computer Vision Lab suggested occlusion orders which differentiate occluding/occluded objects, depth orders which explain the order of distances between objects, and a new deep learning network to portray the dataset's usability.
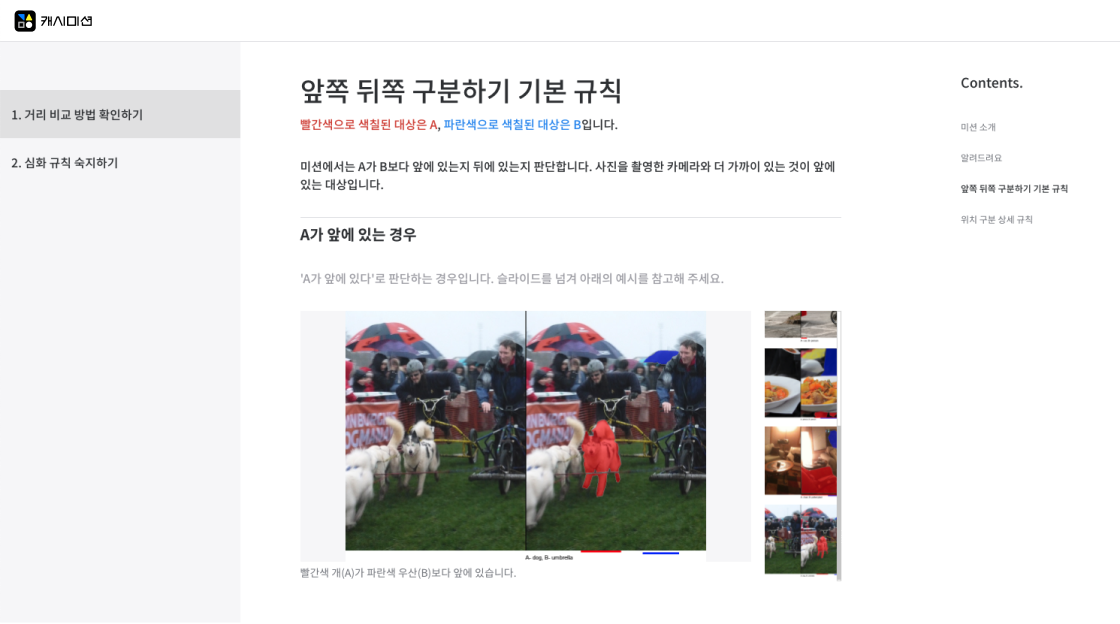
Data were collected and labeled using Cash Mission, Datumo's crowd-sourcing platform.
Approximately 1.45 million combinations of positions of two objects
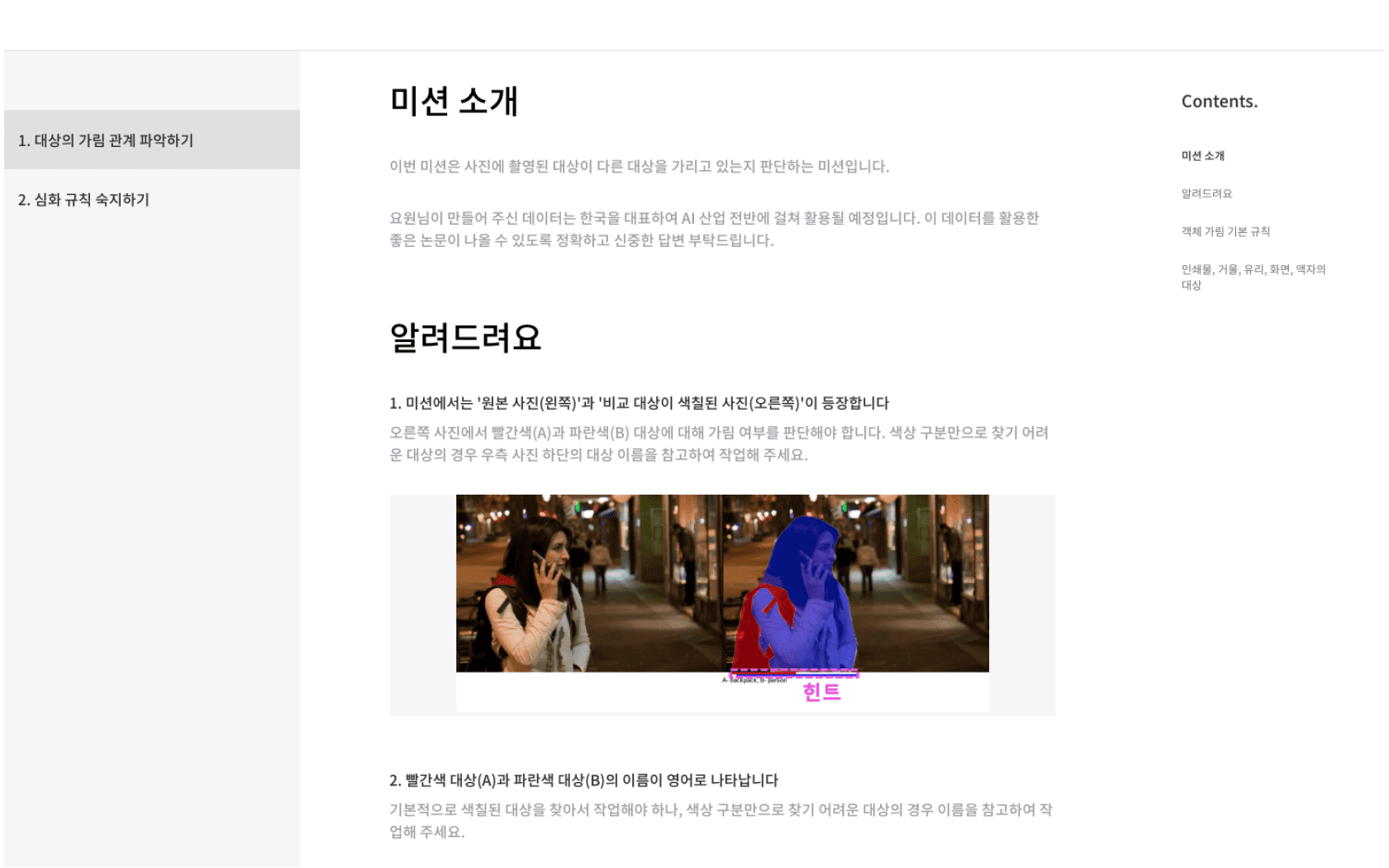
- Approximately 1.45 million combinations of positions of two objects (posterior/anterior, object occlusion)
- Classify objects in photos from COCO dataset into two combinations
- If n objects exist in one image, then sort them into nC2 combinations (ex: 4 objects in an image -> 4C2 -> 6 combinations)
- Location and name of both objects specified on the right side of the original image
Data Collection
Object orientation / Multirange data
Data were collected and labeled using Cash Mission, Datumo's crowd-sourcing platform.

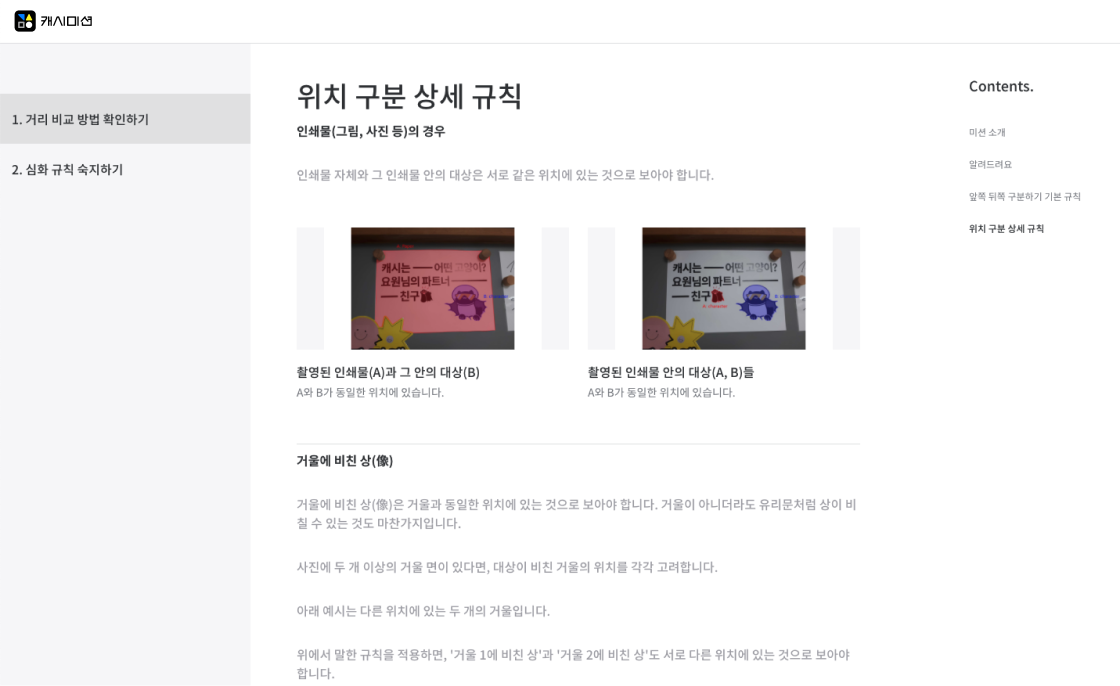
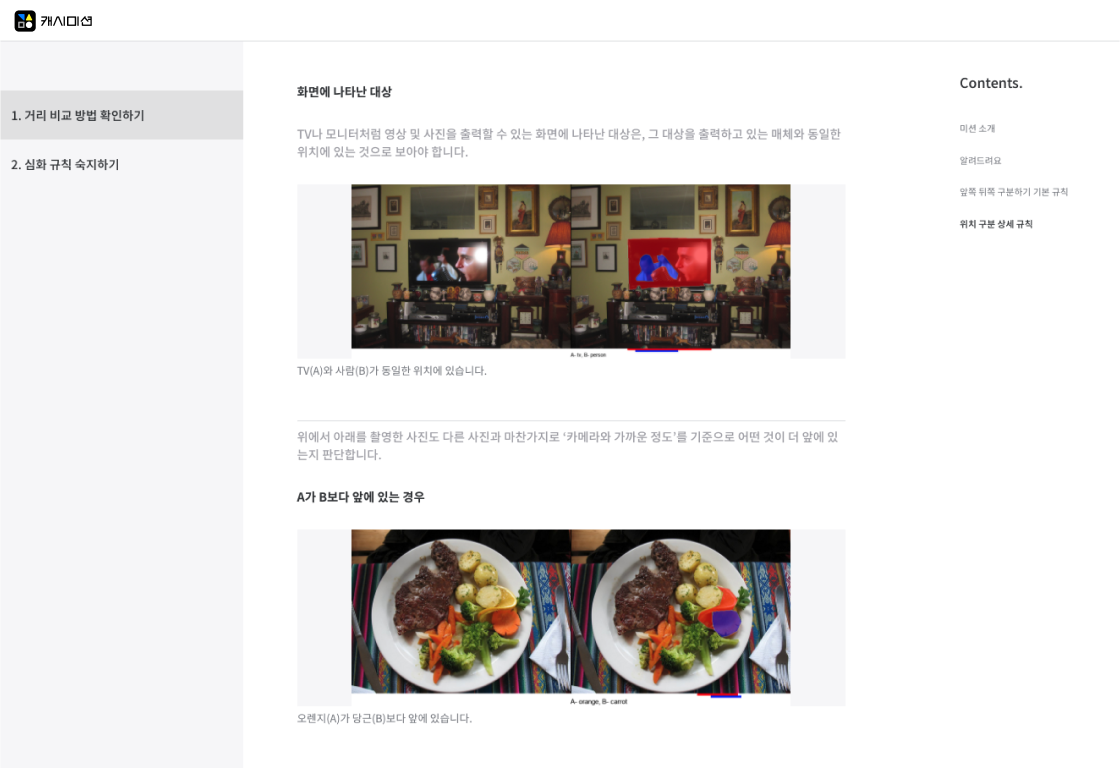
Sample Data
[
{
"img_file_name": "9999_143338_400807.png",
"img_file_url": "https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/9999_143338_400807.png",
"multi_range_ox": true,
"geometric_depth": "A<B",
"count": 2
},
{
"img_file_name": "9999_163526_137336.png",
"img_file_url": "https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/9999_163526_137336.png",
"multi_range_ox": false,
"geometric_depth": "B<A",
"count": 2
},
{
"img_file_name": "9999_163526_138747.png",
"img_file_url": "https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/9999_163526_138747.png",
"multi_range_ox": false,
"geometric_depth": "B<A",
"count": 2
},
{
"img_file_name": "9999_163526_143338.png",
"img_file_url": "https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/9999_163526_143338.png",
"multi_range_ox": false,
"geometric_depth": "B<A",
"count": 2
},
{
"img_file_name": "9999_163526_201728.png",
"img_file_url": "https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/9999_163526_201728.png",
"multi_range_ox": false,
"geometric_depth": "B<A",
"count": 2
},....--
- img_file_name
: img_id__object1id(left)__object2id(right).png - multi_range_ox
: true / false - geometric_depth
: A<B : A is anterior
B<A : B is anterior
A=B : Same orientation - count
: Number of workers participated in the decision-making
Data Collection
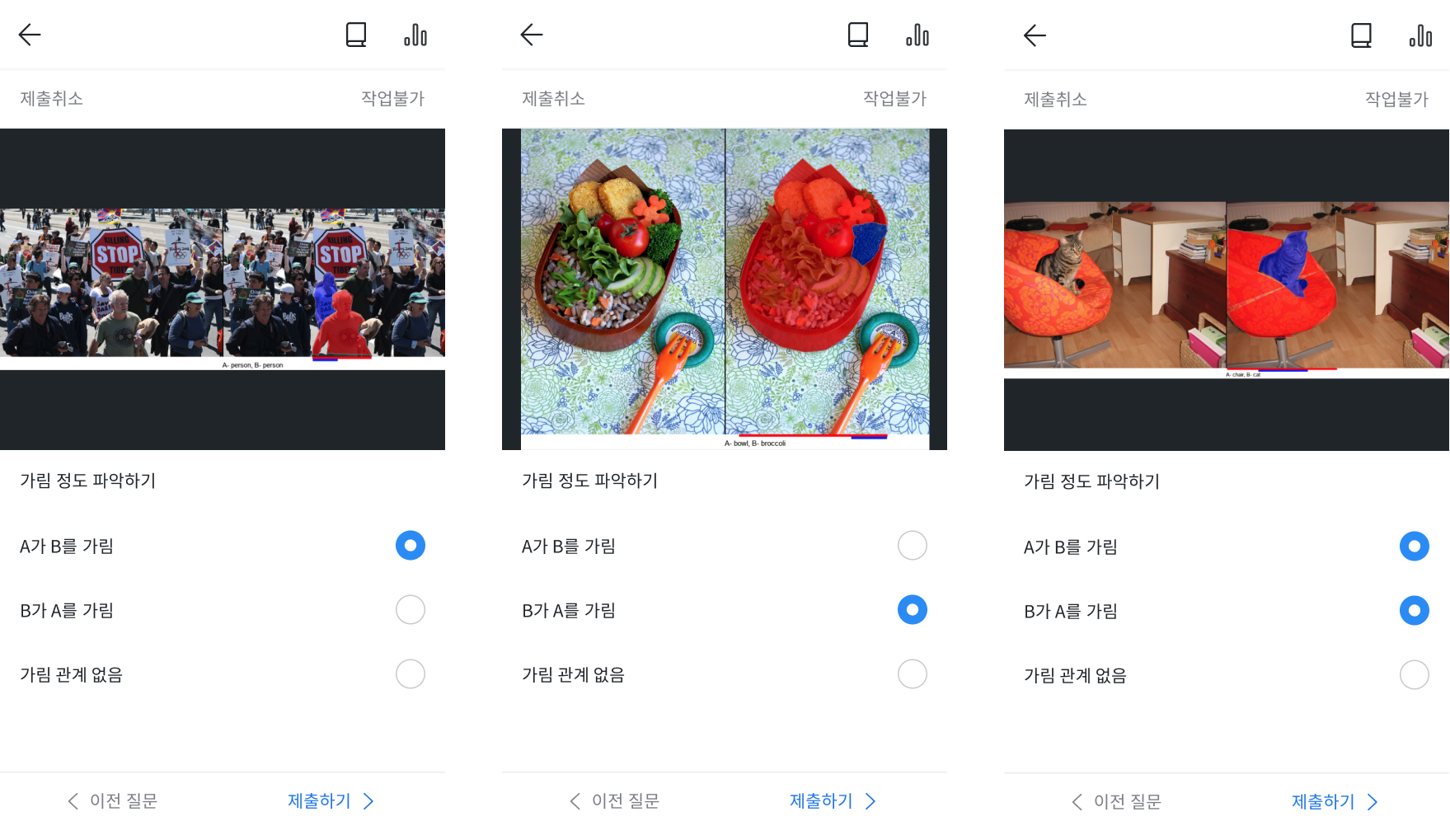
Occlusion information data
Data were collected and labeled using Cash Mission, Datumo's crowd-sourcing platform.
Sample Data
[
{'img_file_name': '498295_1265282_685979.png',
{'img_file_name': '498337_2022230_2014026.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498337_2022230_2014026.png',
'semantic_depth': None,
'count': 3},
{'img_file_name': '498339_1270164_1795559.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1270164_1795559.png',
'semantic_depth': 'A<B',
'count': 3},
{'img_file_name': '498339_1680534_1270164.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1680534_1270164.png',
'semantic_depth': None,
'count': 2},
{'img_file_name': '498339_1680534_1275905.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1680534_1275905.png',
'semantic_depth': None,
'count': 2},
{'img_file_name': '498339_1680534_1795559.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1680534_1795559.png',
'semantic_depth': None,
'count': 2},
{'img_file_name': '498339_1680534_2002662.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1680534_2002662.png',
'semantic_depth': None,
'count': 2},
{'img_file_name': '498339_1693543_1263279.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1693543_1263279.png',
'semantic_depth': 'B<A',
'count': 2},
{'img_file_name': '498339_1693543_1267264.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1693543_1267264.png',
'semantic_depth': None,
'count': 2},
{'img_file_name': '498339_1693543_1270164.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1693543_1270164.png',
'semantic_depth': None,
'count': 2},
...-
[{'img_file_name': '498295_1265282_685979.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498295_1265282_685979.png',
'semantic_depth': 'A<b& B<A',
'count': 2},
{'img_file_name': '498337_2022230_2014026.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498337_2022230_2014026.png',
'semantic_depth': None,
'count': 3},
{'img_file_name': '498339_1270164_1795559.png',
'img_file_url': 'https://cashmission-inputs.s3.ap-northeast-2.amazonaws.com/2000/1/498339_1270164_1795559.png',
'semantic_depth': 'A<B',
'count': 3},
{'img_file_name':
...
- A<B : A occludes B
- B<A : B occludes A
- A<B & B<A : A and B occlude each other
- None : No occlusion
- INVALID : Invalid original image (ex. collaged image, identical objects expressed differently, etc.)
Applications
AI models with 3D information recognition


CC BY-SA
Reusers are allowed to distribute, remix, adapt, and build upon the material in any medium or format, even commercially, so long as attribution is given to the creator. If you remix, adapt, or build upon the material, you must license the modified material under identical terms.
https://creativecommons.org/licenses/by-sa/3.0/deed.en