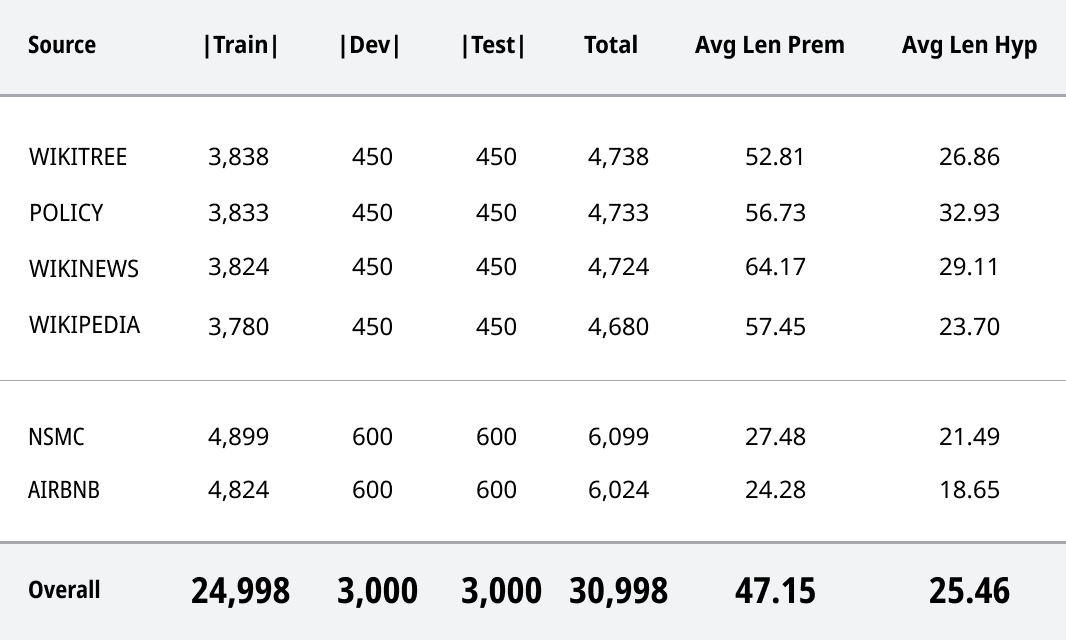
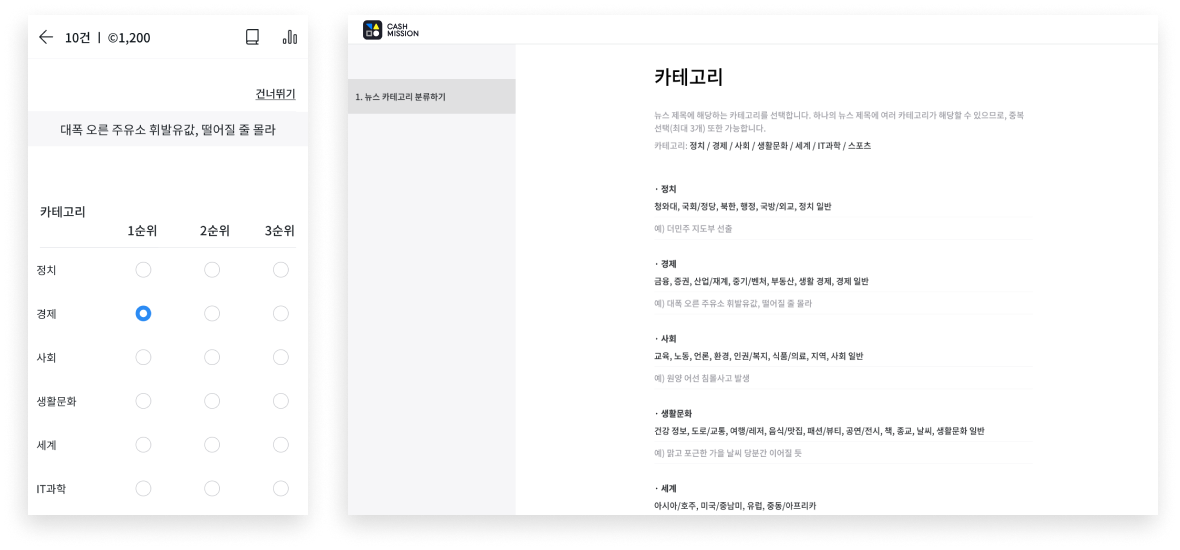
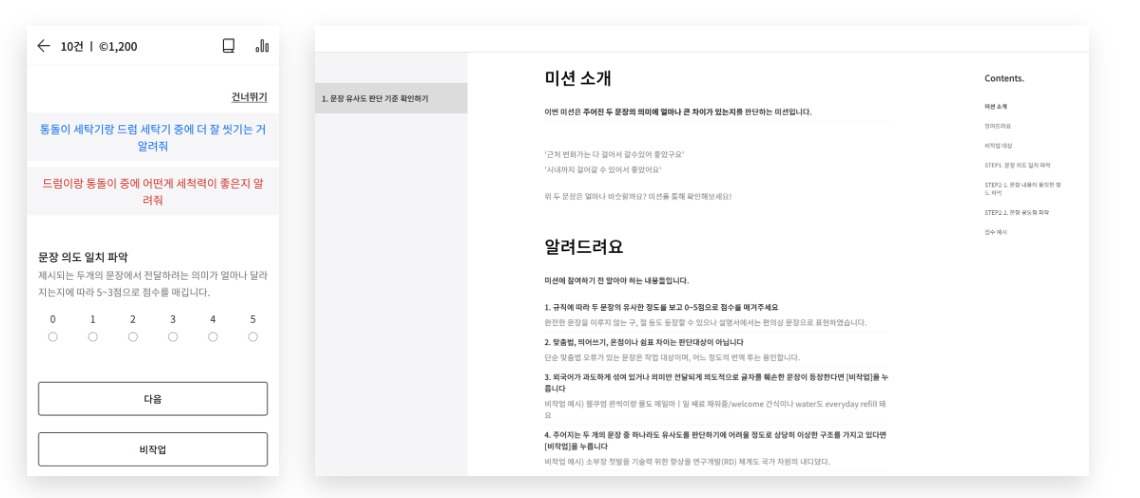
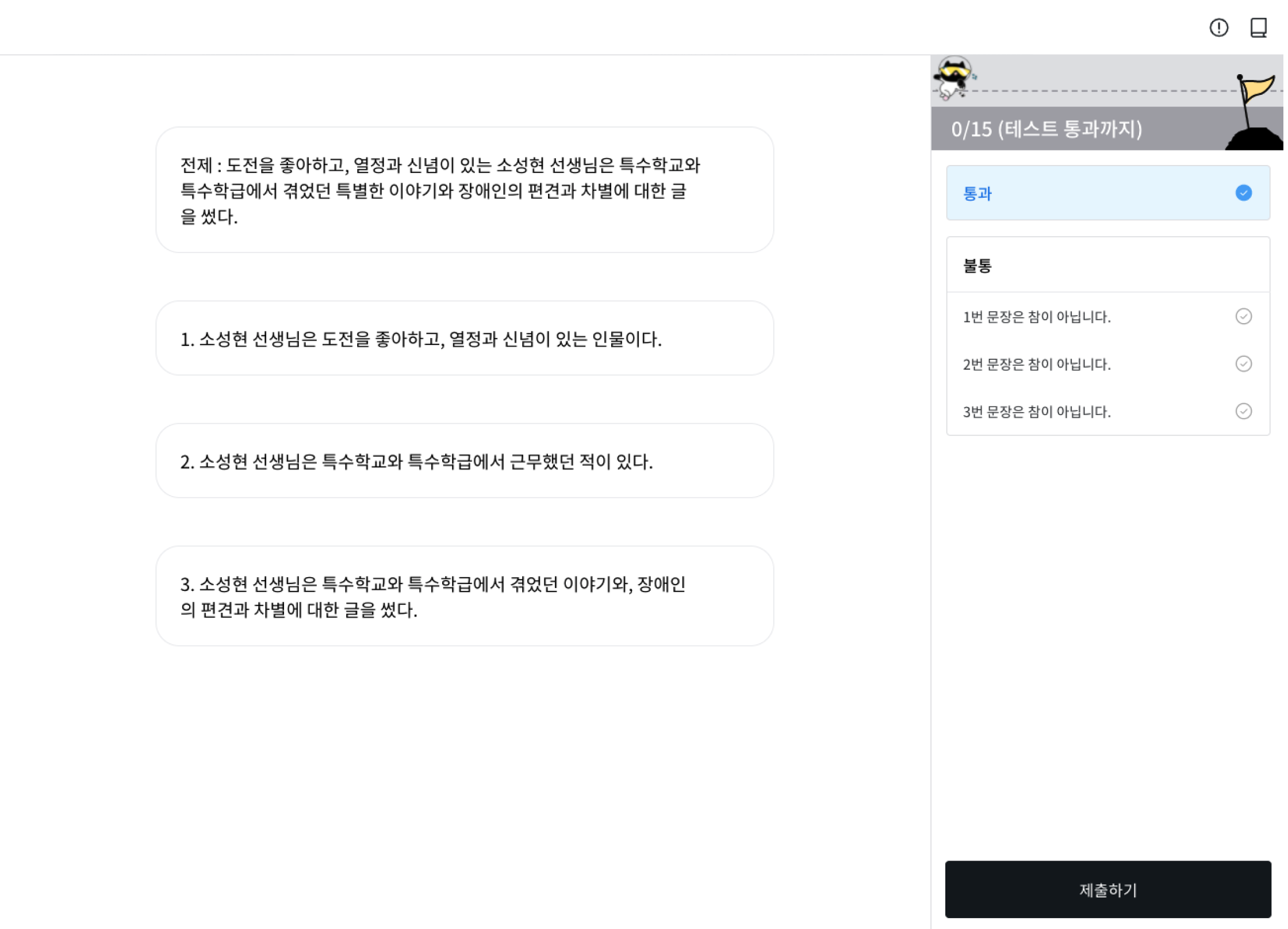
{
"annotatable": {
"parts": [
"s1s1h1",
"s1s1v1"
]
},
"anncomplete": true,
"sources": [],
"metas": {},
"entities": [
{
"classId": "e_1",
"part": "s1s1v1",
"offsets": [
{
"start": 186,
"text": "러시아 기상청에 따르면 혹독한 추위로 악명 높은 모스크바의 낮기온이 22일(현지시간) 7도까지 치솟았다."
}
],
"coordinates": [],
"confidence": {
"state": "pre-added",
"who": [
"user:ryu"
],
"prob": 1
},
"fields": {},
"normalizations": {}
},
{
"classId": "e_2",
"part": "s1s1v1",
"offsets": [
{
"start": 234,
"text": "7도"
}
],
"coordinates": [],
"confidence": {
"state": "pre-added",
"who": [
"user:ryu"
],
"prob": 1
},
"fields": {},
"normalizations": {}
},
{
"classId": "e_1",
"part": "s1s1v1",
"offsets": [
{
"start": 751,
"text": "미국 대형 투자은행인 골드만삭스는 22일 발표한 보고서에서 "올겨울 이상고온으로 난방용 천연가스와 등유 소비가 감소하고 있다"며 "원유 공급 과잉과 세계 경제성장 둔화 등에 따라 약세가 이어지는 에너지 가격을 더욱 끌어내릴 것"이라고 전망했다."
}
],
"coordinates": [],
"confidence": {
"state": "pre-added",
"who": [
"user:ryu"
],
"prob": 1
},
"fields": {},
"normalizations": {}
}
],
"relations": []
}