This Korean offensive language dataset classifies ethically problematic hate speech into 11 categories and uses a 4-point Likert scale to determine the ethicality of sentences.
It was developed in collaboration with TUNIB and HUMANE Lab.
About
Korean Offensive Language Classification (Detection) Dataset
Dataset aims to classify ethically problematic hate speech into 11 categories. Datumo provides high-quality training data for smarter artificial intelligence. This dataset was developed as part of Datumo's AI Dataset Support Program in collaboration with TUNiB, HUMANE Lab, and it is available for free.
TUNiB is a tech startup established in March 2021 by members from the Natural Language Processing team of Kakao Brain. They are creating a global AI chatbot that interacts with people. They operate chatbot services like Dearmate and Bloony, and also run a natural language processing API service called TUNiBridge.
HUMANE Lab, affiliated with the AI Convergence Department at Soongsil University, focuses on researching deep learning and natural language processing technologies to address social issues. Their goal is to publish research findings in internationally renowned CS/Convergence conferences and journals.
Testimonial
"It was extremely challenging to establish consistent criteria for classifying offensive language into 11 categories and distinguishing the intensity of expressions using a 4-level Likert scale.
Due to the subjective nature of classifying offensive language, it posed more challenges in crowd worker training even after reaching a consensus on the criteria. Since offensive language continues to evolve and not all workers are familiar with slang or subtle expressions, there were many corner cases during the labeling process."
Datumo / PM Lee Ji-soo
"Thanks to Datumo's effort in leading the labeling work to match the project's goals as closely as possible, we were able to achieve great results. I appreciate your unstinting investment of both human and material resources. Through multiple Proofs of Concept (PoC) carried out during the collaboration period and continuous communication, we were able to reach our objective. Up until the midpoint of the project, we fine-tuned our mutual fit and established the right guidelines, after which we were able to finish swiftly. During this process, I was able to experience Datumo's systematic process."
TUNiB
"To promote responsible language use, it is crucial to recognize the targets of hidden offensive expressions in text and consider the intensity of their expressions. It was meaningful to collaborate with Datumo and contribute to building a large-scale Korean dataset for this purpose. Working with the competent natural language processing company, TUNiP, was enjoyable. We hope that this dataset will be widely utilized by researchers and students in the field of natural language processing."
HUMANE Lab / Professor Gunwoo Park
Dataset specification
Total dataset: 500,000 sentences
Open dataset: 200,000 sentences (provided by HUMANE Lab)
Selected dataset: Approximately 100,000 sentences (curated by Datumo)
Data Collection and Processing Method
The dataset was based on offensive sentences collected by TUNiB and HUMANE Lab.
Text data processing was performed to categorize offensive expressions into 11 categories and assign scores for each category.
Offensive targets and expressions were tagged in the dataset.
Data Collection
Datumo's crowdsourcing platform, "Cash Mission(App)", was used for the collection and processing of a portion of the data. Crowdsourced workers directrly participated in the offensive expression project-comment tagging mission.
On 'Cash Mission(Web)', a specialist guide team created guides to assist crowd wokers in understanding their tasks.
Partial excerpt from the labeling guide for offensive expression
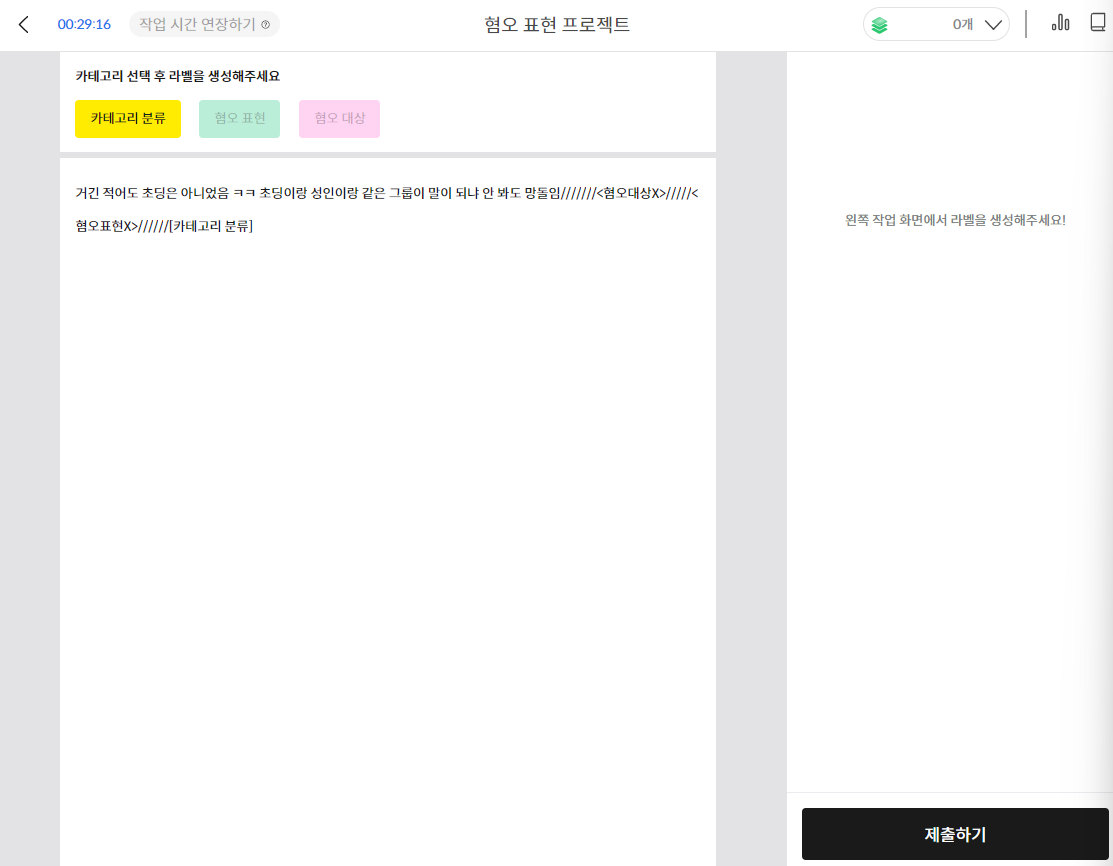
1. Please identify which part of the given sentence is the target for labeling.
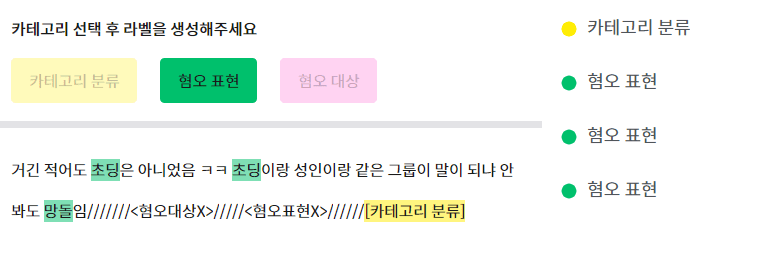
* Offensive Expression: Words or vocabulary that contain aggression towards a specific group or individual with certain attributes.
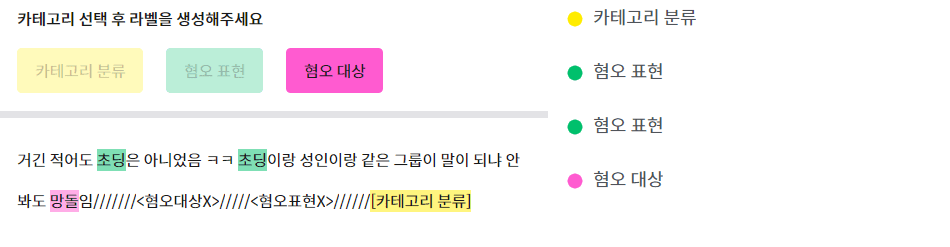
*Target of Offense: The subject or target of the offensive expression.
After selecting the category of offensive expression, create a label.
After selecting the category of the target of offense, create a label.
Development of an AI system for filtering offensive speech.
CC BY-SA
Reusers are allowed to distribute, remix, adapt, and build upon the material in any medium or format, even commercially, so long as attribution is given to the creator. If you remix, adapt, or build upon the material, you must license the modified material under identical terms.